🗄 SQL
SQL is a language for data retrieval and manipulation and other actions executed onto a database.
This article introduces different ways of organizing SQL scripts in .NET projects.
Contents
- Combining ORM and SQL
- SQL inside .NET Projects
- Using Embedded Resources
- File Grouping
- SqlEnum
- Script Content
- SqlExecutor
- Parameters
- Records
- NHibernate Integration
- Using Raw SQL Files
- Using String Literals
- String Concatenation
- Using Repositories
- Database Upgrade Scripts
Combining ORM and SQL
Executing queries onto a database would normally be done through ORM, but if performance is an issue, it can be combined with raw SQL.
SQL inside .NET Projects
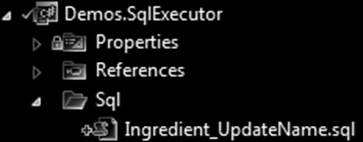
Other techniques, like stored procedures and views were dismissed at one point, in favor of putting the SQL files directly the .NET projects, under a sub-folder named Sql:
Using Embedded Resources
It is preferred to use embedded resources to include the SQL files:
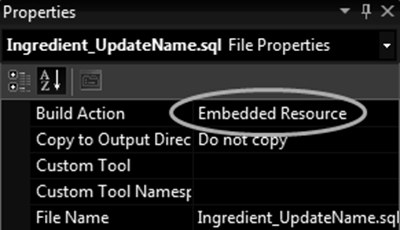
This deploys the SQL together with your EXE or DLL, because compiles the SQL file right into the assembly.
File Grouping
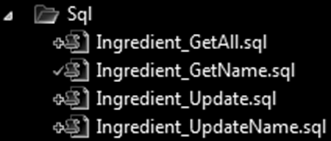
It might be an idea to let the SQL file names begin with the entity type name, so they stay grouped together:
SqlEnum
Then you can put an enum in the Sql folder in your .NET project:
Add enum members that correspond to the file names of the SQL files:
namespace JJ.Demos.SqlExecutor.Sql
{
internal enum SqlEnum
{
Ingredient_UpdateName
}
}
Script Content
The SQL may look as follows:
update Ingredient set Name = @name where ID = @id;
SqlExecutor
The classic way of executing SQL in .NET would be to use System.Data.SqlClient. But in this architecture the SqlExecutor API is used instead.
With an API like that, we can execute SQL command in a strongly-typed way, often with only a single line of code.
An SqlExecutor can be created as follows:
ISqlExecutor sqlExecutor = SqlExecutorFactory.CreateSqlExecutor(
SqlSourceTypeEnum.EmbeddedResource, connection, transaction);
We passed the SqlConnection and SqlTransaction to it.
Then you can call a method that executes the SQL:
sqlExecutor.ExecuteNonQuery(SqlEnum.Ingredient_UpdateName, new { id, name });
The method names, like ExecuteNonQuery, are similar to those of the SqlCommands in the .NET Framework.
Parameters
SQL parameters can be passed along as an anonymous type:
new { id, name }
The name and type of id and name correspond to the parameters of the SQL. You do not need to use an anonymous type. You can use any object. As long as its properties correspond to the SQL parameters:
var ingredient = new IngredientDto
{
ID = 10,
Name = "My ingredient"
};
sqlExecutor.ExecuteNonQuery(SqlEnum.Ingredient_UpdateName, ingredient);
The parameter names are not case sensitive.
Records
You can also retrieve records as a collection of strongly typed objects:
IList<IngredientDto> records =
sqlExecutor.ExecuteReader<IngredientDto>(SqlEnum.Ingredient_GetAll).ToArray();
foreach (IngredientDto record in records)
{
// ...
}
The column names in the SQL are case sensitive!
NHibernate Integration
If you use SqlExecutor in combination with NHibernate you might want to
use the NHibernateSqlExecutorFactory instead of the default SqlExecutorFactory:
ISession session = ...;
ISqlExecutor sqlExecutor =
NHibernateSqlExecutorFactory.CreateSqlExecutor(
SqlSourceTypeEnum.EmbeddedResource, session);
This version uses an ISession. In order for the SQL to run in the same transaction as NHibernate, we made it aware of its ISession.
An implementation of NHibernateSqlExecutorFactory can be found in JJ.Framework.Data.NHibernate.
Using Raw SQL Files
(This feature might not be available in the JJ.Framework.)
It might be a good choice to include the SQL as an embedded resource, but you can also use loose files:
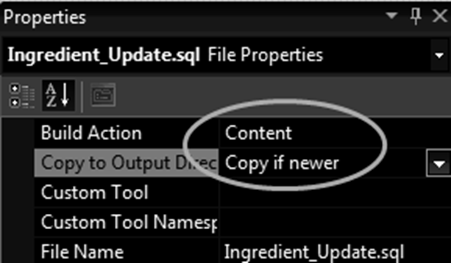
Here is code to create the SqlExecutor and execute the SQL file:
ISqlExecutor sqlExecutor =
NHibernateSqlExecutorFactory.CreateSqlExecutor(
SqlSourceTypeEnum.FileName, session);
sqlExecutor.ExecuteNonQuery(@"Sql\Ingredient_Update.sql", new { id, name });
So the SqlEnum cannot be used here. You’d use a (relative) file path.
Using String Literals
(This feature might not be available in the JJ.Framework.)
It is not recommended to use SQL strings in your code. But it is possible all the same using code like this:
ISqlExecutor sqlExecutor =
NHibernateSqlExecutorFactory.CreateSqlExecutor(
SqlSourceTypeEnum.String, session);
sqlExecutor.ExecuteNonQuery(
"update Ingredient set Name = @name where ID = @id",
new { id, name });
In that case no SQL files have to be included in your project.
But it might make it harder to track down all the SQL of your project and optimize it. Using SQL strings may also circumvent another layer of protection against SQL injection attacks.
String Concatenation
SQL string concatenation is sort of a no-no, because it removes a layer of protection against SQL injection attacks. SqlClient has SqlParameters from .NET to prevent unwanted insertion of scripting. SqlExecutor from JJ.Framework uses SqlParameters under the hood, to offer the same kind of protection. This encodes the parameters, so that they are recognized as simple types or string values rather than additional scripting.
Here is a trick to prevent the use of string concatenation: When you want to filter something conditionally, depending on a parameter being filled in or not, then the following expression might be used in the SQL script’s where clause:
(@value is null or Value = @value)
But there might be exceptional cases where SQL string concatenation would be favorable. Reasons to do so might include:
- You have a (complicated)
SQLselectstatement and wish to take thecountof it. String concatenation may prevent rewriting theSQLstatement twice, introducing a maintenance issue. Bugs would be awaiting as you’d have to change 2SQLscripts simultaneously, to make a change properly, which may easily be overlooked. - Another case where
stringconcatenation might be helpful, is anSQLscript where you wish to include a database name or schema name. - There might be other examples where
SQLstring concatenation might be used as an exception to the rule.
One variation of SqlExecutor included the ability to add placeholders to the SQL files to insert additional scripting for this purpose. (This feature might not be available in the JJ.Framework.)
Using Repositories
The repository pattern is used in this architecture.
The repository pattern can be used together with JJ.Framework.Data.
Using SQL combined with repositories can be simplified using the SqlExecutor from JJ.Framework.Data.SqlClient.
Here is some pseudo-code to demonstrate how it is put together:
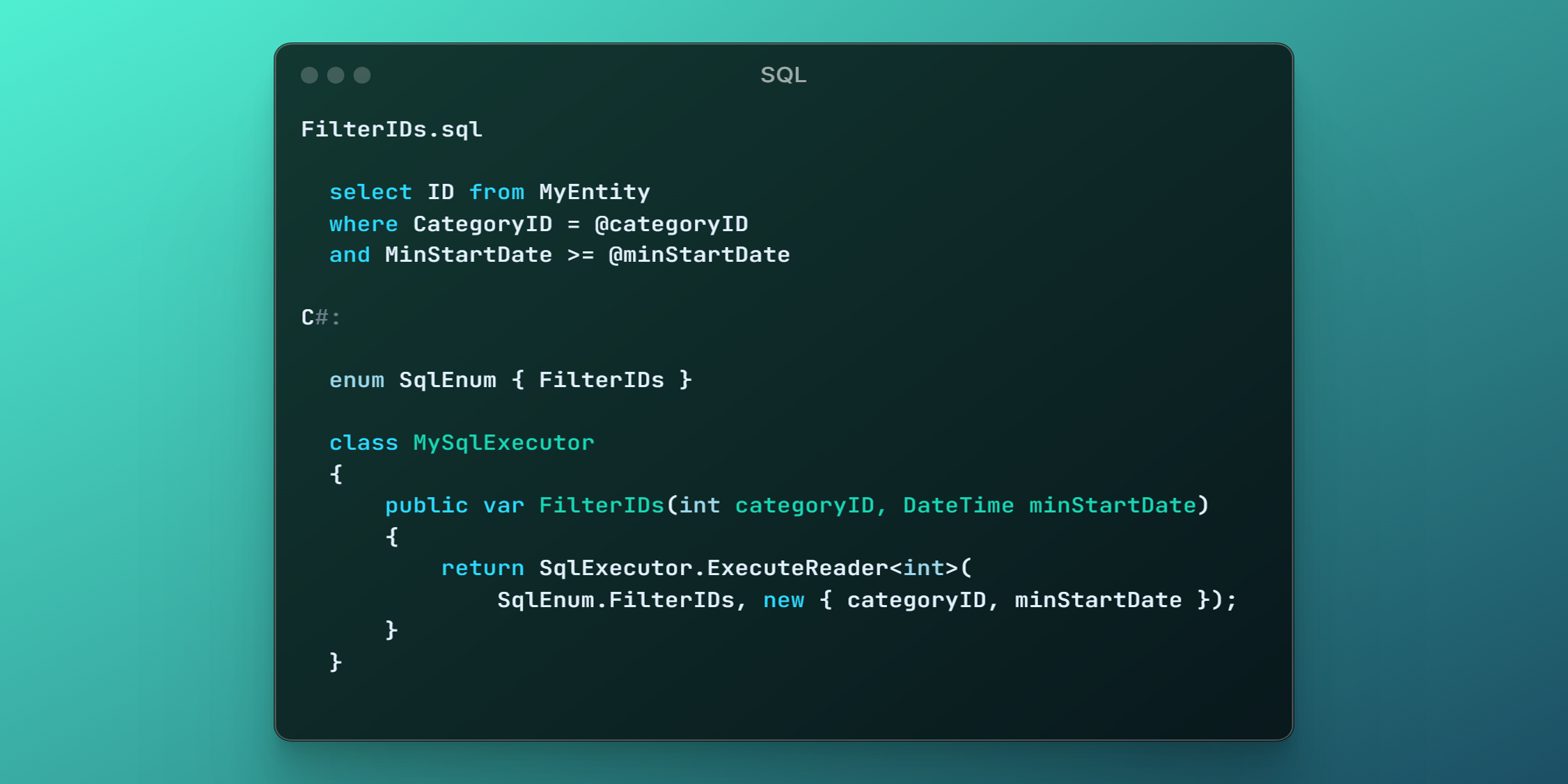
FilterIDs.sql
select ID from MyEntity
where CategoryID = @categoryID
and MinStartDate >= @minStartDate
enum SqlEnum
{
FilterIDs
}
class MySqlExecutor
{
public var FilterIDs(int categoryID, DateTime minStartDate)
{
return SqlExecutor.ExecuteReader<int>(
SqlEnum.FilterIDs, new { categoryID, minStartDate });
}
}
class MyRepository : RepositoryBase
{
public var Filter(int categoryID, DateTime minStartDate)
{
var ids = MySqlExecutor.FilterIDs(categoryID, minStartDate);
var entities = ids.Select(x => Get(x));
return entities;
}
}
interface IMyRepository : IRepository
{
var Filter(int categoryID, DateTime minStartDate);
}
This would result in:
- Keeping all the queries of an entity together in a
repository. - Keeping overview of all the
SQLof all the entities behind anSqlExecutor. - All that data access would be hidden behind
repository interfacesdecoupling the persistence technology.
It may seem overhead all the layers, but it might add up after adding more queries for more entities, that are either SQL or ORM queries. Of course you could skip layers, but this is how it is done in some of the JJ projects.
You might also find a split up into separate assemblies:
MyProject.DataMyProject.Data.EntityFrameworkMyProject.Data.SqlClient
Separating the general things from the technology-specific things.
Database Upgrade Scripts
SQL executed solely for database upgrading, might not be put in the main projects, but a project on the side. Suggestions of how to organize database upgrading might be found here.