[ Draft ]
⚙️ Other Patterns
There are quite a few other design patterns, not specific to any particular software layer: patterns like Wrappers and Factories.
Contents
- Accessor
- Adapter
- Anti-Encapsulation
- Anti-Magic Booleans
- Comma Appending
- Comments
- Constructor Inheritance
- DebuggerDisplays
- Executor
- Factory
- Factory-Base-Interface
- Helper
- Info
- Inheritance-Helper
- Initialization and Finalization
- Mock
- Name Constants
- NullCoalesce
- Plug-In Model
- Progress and Cancel Callbacks
- Rich Models
- Singular, Plural, Non-Recursive, Recursive and WithRelatedEntities
- TryGet
- TryGet-Get-GetMany
- Wrapper
Accessor
An Accessor class allows access to non-public members of a class. This can be used for testing or for special access to a class from special places. JJ.Framework.Reflection has an implementation of a reusable Accessor class.
Adapter
< TODO: Describe what an adapter is in general and what kind of variations you can think of. >
Anti-Encapsulation
Encapsulation makes sure a class protects its own data integrity. Anti-encapsulation is the design choice to let a class check none of its data integrity. Then you know that something else is 100% responsible for the integrity of it, and the class itself will guard none of it.
The reason not to use encapsulation is that it can go against the grain of frameworks, such as ORM's and data serialization mechanisms.
Anti-encapsulation can also be a solution to prevent spreading of the same responsibility over multiple places. If the class cannot check all the rules itself, it may be better the check all the rules elsewhere, instead of checking half the rules in the class and the other half in another place.
Anti-Magic Booleans
Allows for a syntax that looks like a boolean parameter that you do not have to assign a value to:
Contains(matchCase)
Contains(matchCase: true)
Contains(matchCase: false)
See: Anti-Magic Booleans
Comma Appending
Different ways to append a comma only in between elements.
Example 1:
string concatenatedElements = string.Join(",", elements);
Example 2:
var sb = new StringBuilder();
int count = elements.Count;
for (int i = 0; i < count; i++)
{
string element = elements[i];
sb.Append(element);
bool isLast = i == count - 1;
if (!isLast)
{
sb.Append(',');
}
}
Example 3:
var sb = new StringBuilder();
bool mustAppendComma = false;
foreach (string element in elements)
{
if (mustAppendComma) sb.Append(',');
mustAppendComma = true;
sb.Append(element);
}
Comments
Comments in Summaries
You might put comment for members in <summary> tags.
| Recommended | Less Preferred |
|---|---|
|
|
Reason:
Your comment might be valuable from the outside for others to see. Your summary would show up when hovering over a member.
Comments in English
| Recommended | Less Preferred |
|---|---|
|
|
Reason:
English is basically the main language in IT. A broader reach of people might be able to read your comments.
No Comments without Info
Avoid comments that do not add information.
| Recommended | Less Preferred |
|---|---|
|
|
Reason:
Less visual clutter. Reading it might not be worth the time.
No Unused / Outcommented Code
Avoid leaving around unused or outcommented code. If necessary, you can move it to an Archive folder.
Reason:
Unused code might clutter your vision. It may also give the impression, that it was outcommented in error.
More information
Here’s a way to centralize and reuse doc comments efficiently: Doc-Only Members
Constructor Inheritance
Sort of forces a derived class to have a constructor with specific arguments. Constructors are not inherited, but inheriting from a base class that has specific constructors forces your derived class to call that base constructor, often leading to exposing a similar constructor in the derived class.
DebuggerDisplays
See: Using the DebuggerDisplay Attribute
< TODO: Describe how I handle DebuggerDisplays. Snippet of text: DebuggerDisplays with private property DebuggerDisplay. >
Executor
Executor classes are classes that encapsulate a whole process to run. For processes that involve more than just a single function, for instance downloading a file, transforming it and then importing it, involving infrastructure end-points and possibly multiple back-end libraries.
By giving each of those processes its own Executor class, you make the code overviewable, and also make the process more easily runnable from different contexts, e.g. in a scheduler, behind a service method or by means of a button in a UI or in a utility.
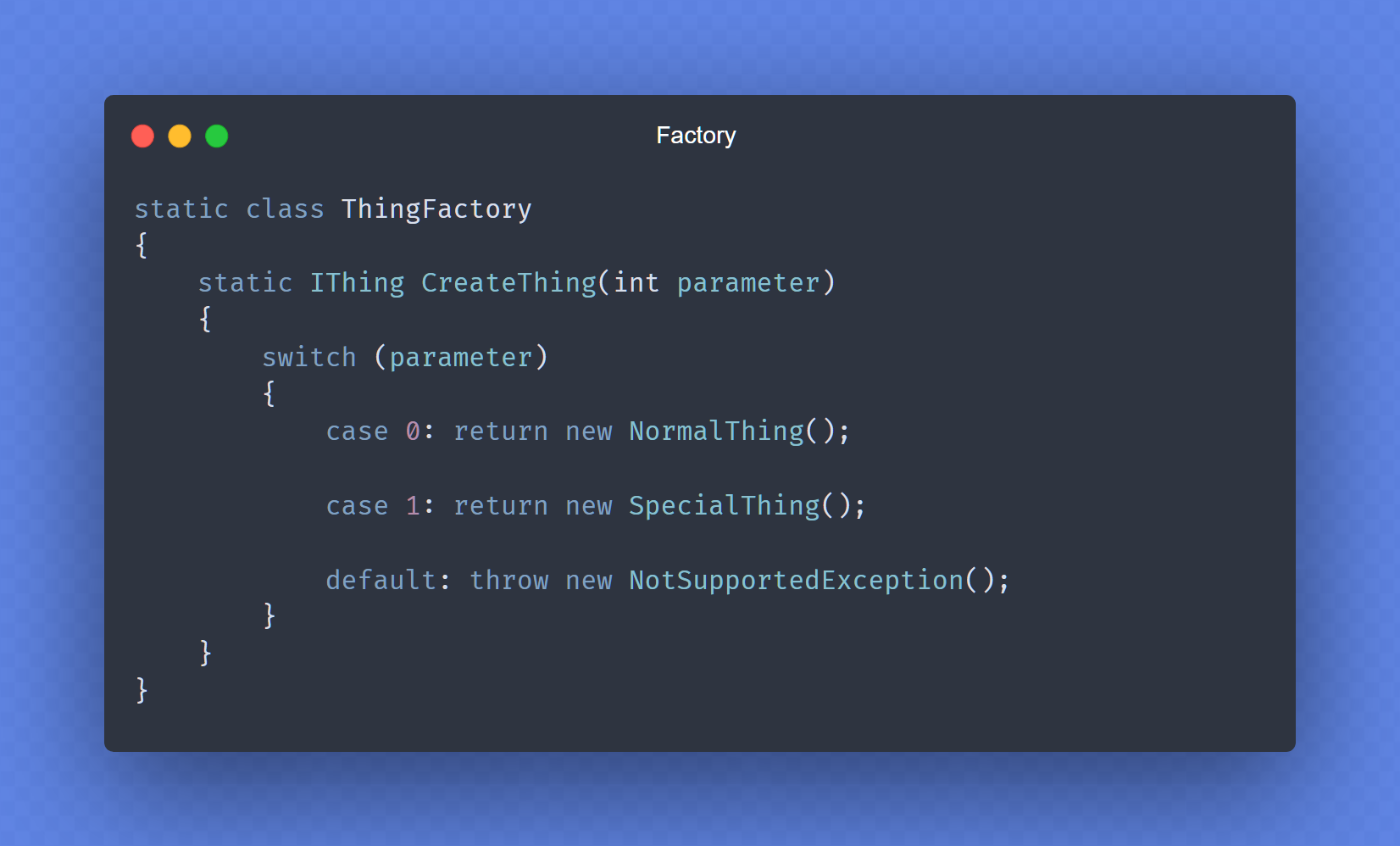
Factory
A Factory class is a class that constructs instances. But it usually means that it creates a concrete type, returning it as an abstract type. The concrete type that is instantiated depends on the input you pass to the Factory's method:
public static class ThingFactory
{
public static IThing CreateThing(int parameter)
{
switch (parameter)
{
case 0:
return new NormalThing();
case 1:
return new SpecialThing();
default:
throw new Exception(
String.Format("parameter value '{0}' is not supported.", parameter));
}
}
}
A Factory class is used if you want to instantiate an implementation of a base class or interface, but it depends on conditions which implementation it has to be or if you wish to abstract away knowledge of the specific concrete types it produces.
A class that returns instances with various states is also simply called a Factory, even though no polymorphism is involved.
(The classic implementation is not used here, which is a static method in a base class.)
Factory-Base-Interface
The Factory-Base-Interface pattern is a common way the Factory pattern is applied. Next to a Factory, as described above in the Factory pattern, you give each concrete implementation that the Factory can return a mutual interface, which also becomes the return type of the Factory method. To also give each concrete implementation a mutual base class, with common functionality in it, and also to sort of force an implementation to have a specific constructor (see ‘Constructor Inheritance’).
Helper
Helper classes are static classes with static methods that help with a particular aspect of programming. They can make other code shorter or prevent repeating of code, for functions that do not require any more structure than a flat list of methods.
The word Helper might also be used more generally. Like something that ‘helps’ in general. For instance a project might have a Helpers folder with a limited number of (smaller) classes in it.
Info
Info objects are like DTO’s in that they are usually used for yielding over information from one place to another. Info objects can be used in limited scopes, internal or private classes and serve as a temporary place of storing info. But Info objects can also have a broader scope, such as in frameworks, and unlike DTO’s they might have constructor parameters, auto-instantiation, encapsulation and other implementation code.
Inheritance-Helper
One weakness of inheritance in .NET might be, that there is no multiple inheritance: you can only derive from one base class. This can lead to problems programming a base class, because one base will offer you one set of functionalities and the other base the other functionalities. (See the Cartesian Product of Features Problem.) To still use inheritance to have behaviors turned on or off, but not have an awkward inheritance structure, and problems picking what feature to put at which layer of inheritance, you could simply program Helper classes (static classes with static methods) that implement each feature, and then use inheritance, letting derived classes delegate to the Helpers, to give each class a specific set of features and specific versions of the features, to polymorphically have the features either turned on or off. You will still have many derived classes, but no arbitrary spreading of features over the base classes, and no code repetition either.
This allows you to solve what inheritance promises to solve, but does not do a good job at on its own. It basically solves the Cartesian Product of Features Problem, the problem that there is no multiple inheritance and the problem with big hairy base classes, all weakneses of inheritance.
Initialization and Finalization
Cleanup code should be symmetric to the set-up code. Build something up in the constuctor then dispose things in the finalizer, start a service at startup then stop a service at shutdown, etc. If in the constructor you bind an event, then in the destructor you unbind it.
You can also choose to implement IDisposable. This is useful if you want to be able to explicitly trigger finalization. Finalizers/destructors only go off when the garbage collector feels like it, and you might want to imperatively tell an object to clean up its stuff.
-
If you implement IDisposable, call Dispose from the finalizer/destructor.:
~MyClass { Dispose(); } -
Make sure the dispose can successfully run regardless of state, so check any variable you might use for null first and be tollerant towards null.
public void Dispose() { _myConnection?.Close(); } -
Also call
GC.SuppressFinalize()in theDispose()method, because then the garbage collector will skip a few unneeded steps in getting rid of theobject.
Mock
A Mock object is used in testing as a replacement for a object used in production. This could be an Entity model, an alternative Repository implementation (that returns Mock Entities instead of data out of a database). A Mock object could even be a database record. Unlike other patterns the convention is to put the word Mock at the beginning of the class rather than at the end.
Name Constants
To prevent typing in a lot of strings in code, make a static class with constants in it, that become placeholders for the name.
E.g. ViewNames, with constants in it like this:
public static class ViewNames
{
public const string Edit = "Edit";
}
the name of the constant would be exactly the same as the string text.
Everywhere you need to use the name, refer to the constant instead of putting a literal string there.
This prevents typing errors and makes “Find all References” possible.
< TODO: Consider not assinging the string value at all, but using nameof(ViewNames.Edit). Consider using nameof() over an existing member to begin with. >
NullCoalesce
< TODO: See NullCoalesce (ViewModels) and write some good text here. >
Plug-In Model
< TODO: Describe my implementation of a nice plug-in model including the ReflectionHelper.GetImplementation methods. >
Progress and Cancel Callbacks
To make a process cancellable and report process without being dependent on the presentation framework, you can simply pass a few callback delegates to a method or class.
public Excute(Action<string> progressCallback, Func<bool> isCanceledCallback)
{
progressCallback("Starting.");
if (isCanceledCallback())
{
progressCallback("Cancelled.");
return;
}
// ...
progressCallback("Finished.");
}
It depends on your problem whether those callbacks are nullable and you should do the appropriate null-checks depending on the situation.
< TODO: Add explanations and code examples about the client code. >
Sometimes it is useful to separate Cancel into two: Canceling and Canceled. This is because a process might not cancel immediately. A UI should not immediately enable a Start button again after the user pressed Cancel. A isCancelingCallback then allows the client to signal to the process that cancellation is requested. And an isCanceledCallback will let the process signal the client that cancelation has complete, so it can enable the start button again.
Rich Models
< TODO: Write story with pros and cons. Include:
>> Arch: another downside of rich models is the magic of it. You are not sure what happens and all sorts of non-obvious side-effects may go off.
- Arch: anemic models and separation of concerns and no rich models can have the consequence that you loose identity and instance integrity, because derived structures are more common. For controls for instance, with gesture events, the original object needs to be found and raised an event on, and you cannot get away with doing it on a derived object unless you clone everything. Not sure how to descrive this clearly. It is about rich models vs. anemic models and when and how to apply which and what are the pros and cons and I do not have a clear image of that yet.
- Explain the problems with rich models in the business layer comprised of derived classes out of the persistence layer, that extend the model with specific relations, constraints and rules, that you do not enforce in the persistence layer.
` Problems with putting it in the business layer include that the persistence layer does not know how to instantiate the derived class, so it must instantiate the base class. Also: if rules are strictly enforced in an extended entity model, it is hard to separate creating Entities from validating it, so instead of user-generated validation messages, you might get exception messages instead.
Problems with putting the specialized classes in the persistence layer include that the entity model must stay as clean as possible: anything you put in the data layer is hard to get rid of.
When you do need an business logic interfacing that is comprised of an ‘extended’ entity model, then you cannot really use inheritance. You might be able to create a facade class that creates a wrapper class around the ‘base’ class out of the entity model.
Currently the choice is to not make an extended entity model in the business layer.
- Arch: against rich models: You want your entity model to be a direct depiction of what is actually stored, so that you have control over that. If it is obscured, this means less control over what is going on. >`
< TODO: Compare rich models with the 2D separation of concerns. >
Singular, Plural, Non-Recursive, Recursive and WithRelatedEntities
When processing object structures, it is best to split everything up into separate methods.
Every Entity type will get a method (the ‘singular’ variation) that processes a single object. That method will not process any underlying related items, only the one object.
In case of conversions from one object structure to another, every destination Entity gets a ‘singular’ method, not the source Entity, because that would easily create messy, unmanageable code.
A ‘plural’ method processes a whole list of items. ‘Plural’ methods are less useful. Prefer ‘singular’ methods over ‘plural’ ones. ‘Plural’ methods usually do not add anything other than a loop, which is too trivial to create a separate method for. Only when operations must be executed onto a whole list of objects (for instance determining a total price of a list of items or when there are specific conditions), it may be useful to create a separate ‘plural’ method.
‘Singular’ or ‘plural’ methods do not process related Entities unless they have the method suffix WithRelatedEntities or Recursive at the end of the method name. Keep the Recursive and RelatedEntities methods separate from the not-WithRelatedEntities methods. Related Entities’ means Entities intrinsically part of the Entity, not links to reused Entities. Also, not the parent.
There is a subtle difference between WithRelatedEntities and Recursive. They are similar, but Recursive processing can pass the same object type again and again, while processing with related Entities processes a tree of objects, in which the same object type does not recur at a deeper level.
Finer details about the ‘singular’ form:
- They do not process child
Entities, they can however link to reusableEntities, such asenum-like types, or categories. - They usualy do not assign a parent. The caller of the ‘singular’ form does that. That way methods are more independent of context and better reusable and code better rewritable. There are exceptions to that rule.
Here is an example of some ‘singular’, ‘plural’, non-Recursive and Recursive methods. Note that the words ‘singular’ and ‘plural’ are not used in the method names.
private class MyProcess
{
private StringBuilder _sb = new StringBuilder();
public string ProcessRecipeRecursive(Recipe recipe)
{
if (recipe == null) throw new NullException(() => recipe);
ProcessRecipe(recipe);
ProcessIngredients(recipe.Ingredients);
ProcessRecipesRecursive(recipe.SubRecipes);
return _sb.ToString();
}
private void ProcessIngredients(IList<Ingredient> ingredients)
{
_sb.AppendLine("Ingredients:");
foreach (Ingredient ingredient in ingredients)
{
ProcessIngredient(ingredient);
}
}
private void ProcessIngredient(Ingredient ingredient)
{
_sb.AppendLine(String.Format("{0} {1} ({2})", ingredient.QuantityDescription, ingredient.Name, ingredient.ID));
}
private void ProcessRecipesRecursive(IList<Recipe> recipes)
{
_sb.AppendLine("Sub-Recipes:");
foreach (Recipe recipe in recipes)
{
ProcessRecipeRecursive(recipe);
}
}
private void ProcessRecipe(Recipe recipe)
{
_sb.AppendLine(String.Format("Recipe: {0} ({1})", recipe.Name, recipe.ID));
}
}
TryGet
A combination of a TryGet method and a Get method (e.g. TryGetObject and GetObject) means that TryGet would return null if the object does not exist and Get would throw an Exception if the object does not exist.
Call Get if it makes sense that the object should exist.
Call TryGet if the non-existence of the object makes sense.
If you call a TryGet you should handle the null value that could be returned.
TryGet can throw other Exceptions, even though it does not throw an Exception if the object does not exist.
TryGet-Get-GetMany
Often you need a combination of the three methods that either get a list, a single item but allow null or get a single item and insist it is not null. You can implement the plural variation and base the Get and TryGet on it using the same kind of code every time:
public Item GetItem(string searchText)
{
Item item = TryGetItem(searchText);
if (item == null)
{
throw new Exception(String.Format("Item with searchText '{0}' not found.", searchText));
}
return item;
}
public Item TryGetItem(string searchText)
{
IList<Item> items = GetItems(searchText);
switch (items.Count)
{
case 0:
return null;
case 1:
return items[0];
default:
throw new Exception(String.Format(
"Multiple items found for searchText '{0}'.", searchText));
}
}
public IList<Item> GetItems(string searchText)
{
return _items.Where(x => !String.IsNullOrEmpty(x.Name) &&
x.Name.Contains(searchText))
.ToArray();
}
The GetItem and TryGetItem methods are the same in any situation, except for names and Exception messages. Only the plural method is different depending on the situation.
Wrapper
A Wrapper class is a class that wraps one or more other objects. This can be useful in various situations. You might give the Wrapper additional helper methods that the wrapped object does not have. You might dispose the underlying Wrapper object and create a new one, keeping the references to the Wrapper object in tact even though the Wrapped object does not exist anymore. You may hide a specific object in a Wrapper and give it an alternative interface, you might wrap multiple objects in one Wrapper to pass them around as a single object for convenience.